
Overview : Language Modelling
- Generation을 위해 Language Modelling을 알아야 하는데 generate를 하지는 않고, scoring을 한다.
- 문장을 input으로 받아서 input에 대한 확률을 내뱉는다. (단어 나열에 확률을 부여하는것)
- Sentence Generation과 Scoring은 Equal model이다.
- Scoring function을 살짝 바꿔서 문장의 prefix등을 보고 partial score를 예측할 수 있다면 efficient하게 search할 수 있다.
Autoregressive Language Modelling
- sequence가 주어졌을 때 어떻게 probability distribution을 계산할지.
- token들이 하나씩 주어질 때 다음 token의 확률이 뭐가 나올지 쭉 곱하는 것. conditional probability생각.
- 좋은 이유 : unsupervised문제를 supervised problem으로 바뀐다. 각각의 conditional들을 보면 input 과 output pair에 대해 학습하게 되기 때문.
- sentence scoring즉 language modelling은 sentence classification을 아주 많이 하는 문제가 된다.
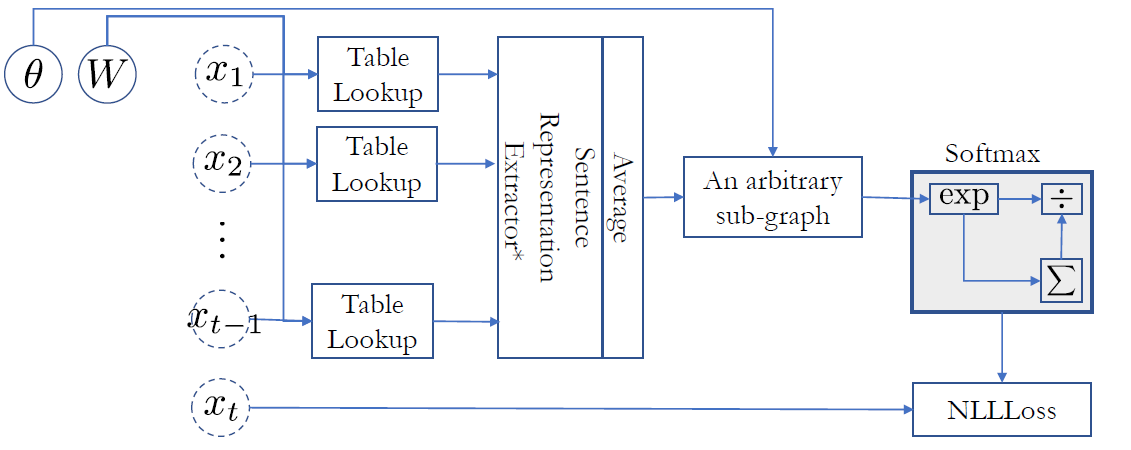
- 각각의 conditional distribution확률을 1~t-1번째 token이 주어졌을 때, t번째 token을 classification하는 model을 만드는 것과 똑같다. sentence representation 5가지 배운것 중에 사용하고, 실제 데이터에 있었던 token의 probability가 높아지도록.
- loss term은 negative log probability가 되고 쭉 더하는 것.
- 문장이 얼마나 likely한지 보는 예제 (6-7쪽)


- Score가 negative likelihood loss와 똑같다. 즉, 자주 나오는건 스코어가 높아지도록!
N-Gram Language Models
NN 이전에는 어떻게 했을까?
IBM등에서, speech recognition을 하기 위해 language modelling을 해야한다고 접근.
- Machine translation도 가장 말이되는 문장을 후보군에서 뽑는 것.
- MLE
- N-gram Probabilities : 앞에 N개가 나왔을 때 확률
- N개의 preceding token이 나온 상태에서.
- 동전을 던져보고 몇 번 head로 떨어지는 지 세어서 전체 횟수를 나누면 bernoulli의 p를 찾는것. (MLE)
도서관, 지식인, wikipedia등의 데이터셋에서 전체 단어 수를 세고 N-Gram table을 만들어서 phrase들이 몇 번 나왔는지 알 수 있다.
- 이 N그램이 몇번 나왔는지/ 앞에 N-1개나왔을 때 다른 단어까지 뭐가나왔는지 토탈넘버
- 이렇게 계산하면 된다.
예제 : (12쪽) New York University
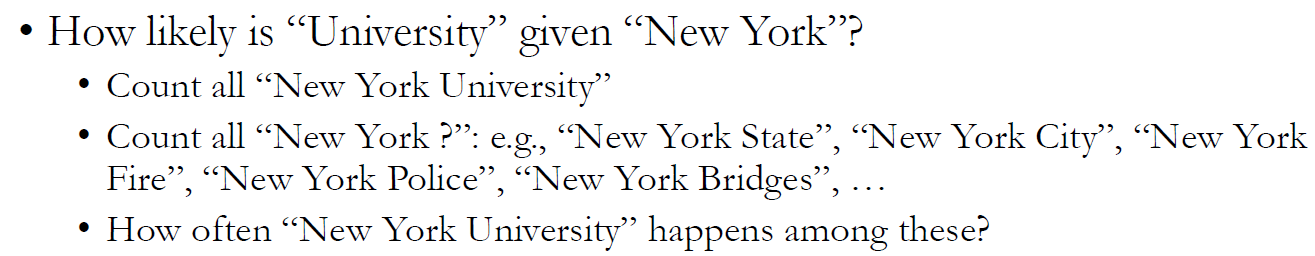
하지만 N-Gram Language Model의 두 가지 큰 문제점이 있다.
Data Sparsity
- a lion is chasing a llama
- chasing a llama라는게 처음 나와서 확률이 0이 되어버리는 것.
Inability to capture long-term dependencies
- 멀리 떨어져있는 단어끼리 연관되어 있어서 N gram에 잡히지 않는 경우
- context사이즈를 늘리고, n을 늘리면 되긴 하는데, N이 커지면 커질 수록 sparsity가 커지게 된다 .
- 영어는 N=7이면 거의 완벽하게 맞출 수 있다.
- 예제 : “The same stump which had impaled the car of many a guest in the past thirty years and which he refused to have removed“
- 앞의 4 단어만 보면 마지막에 removed라는 단어가 나올거라는걸 맞추기 어렵다.
- 문장 뜻 : he라는 사람의 guest들이 30년동안 나무 그루터기때문에 차가 계속 걸렸었는데 he는 그걸 30년동안이나 stump를 없애는걸 거부했던 나쁜놈이라는 뜻임 ㅇㅇㅇ 이름안나오고 He라는게 갑자기 처음나와서 헷갈렸음
이 문장 처음 본 Duke대 친구 반응 : “이거 무슨 고대영어야? 아니면 수능영어?”
- Common한 sentence도 잘 맞추면서 cornerside를 잘 맞추는 것도 중요하다.
Traditional Solutions
Data Sparsity
- count가 0인 경우들이 있어서 문제가 된다. → smoothing
- 하지만 이거도 말이 안됨. chasing a llama와 chasing a star둘다 0.1을 받는게 이상.
- Backoff
- n-1gram을 본다. chasing a llama확률을 0으로 두는게 아니라 a llama로 보는것.
- Kneser-Ney method가 좋다.
- Kneser smoothing쓰면 영어는 거의 완벽하게 된다.
- KenLM open source를 사용하면 된다.
- https://operatingsystems.tistory.com/entry/Data-Mining-Smoothing-Techniques
- 이 블로그 포스트가 이해하는데 도움이 되고 좀 더 자세한 설명이 있다.
Long-Term Dependency
- count based로는 해결 못한다.
- 문장이 있으면 DAG를 만들어서 연결되어 있는 단어들은 grammatically 거리가 가깝고, 아니면 멀고.
- stump로 removed가 바로 연결 되는 것
- dependency parsing을 먼저 해야된다는 문제가 있다.
- 두 문제를 같이 해결해야 하지만 쉽지 않다
Neural N-Gram Language Model
NN을 사용하면 두 가지 문제를 다 해결하는 노력을 할 수 있다.
- Neural Language Model로 data sparsity로 해결을 제시.
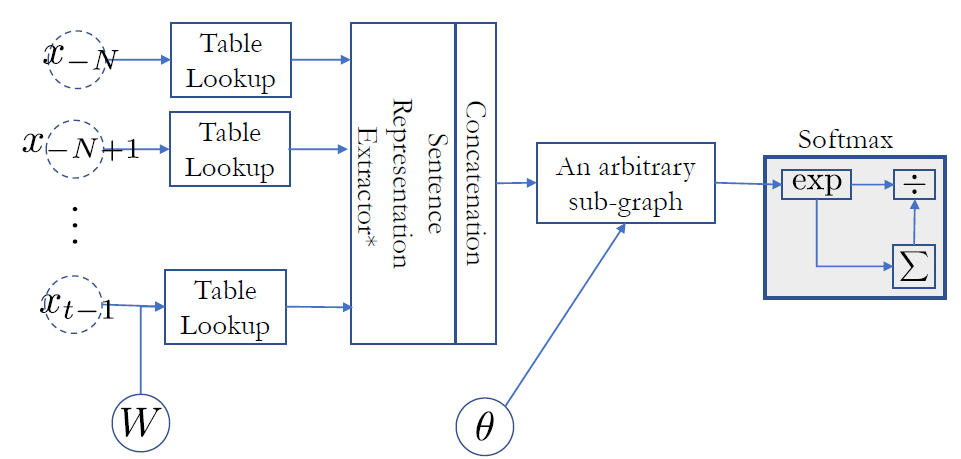
- input으로 ngram을 벡터로 만들고 (구체적으로 아주 단순하게 그냥 concatenate함)
- size가 같은 벡터가 나오게 됨
- 그래프를 지나서 softmax를 하고 sum 해서 나눈다.
- DAG가 만들어지면 backpropagation으로 학습시킬 수 있다.
- 이렇게 하면 countbased와 다르게 training set에 나오지 않은 n-gram에 대해서도 probability를 계산할 수 있게 된다.
Data Sparsity가 왜 생기는가?
- N-gram자체가 test할 때 나오고 train 할 때 없었어서.
- discrete space에서 계산해서 그런거다. 문제점. 어떤 token들이 비슷한지 알 수 없다.
- NN language model은 생각보다 간단하게 이 문제를 해결한다.
- chasing a llama와 비슷한 다른 문장들 (cat, dog, deer)의 n-gram은 0이 아니어서.
- Token representation단에서 각종 mammal들이 비슷하게 붙어 있게 된다. 자연스럽게 distribution이 비슷해진다.
처음 보는 token이어도 continuous space안에서는 굉장히 가까운 곳에 붙어있게 되는 것이다.
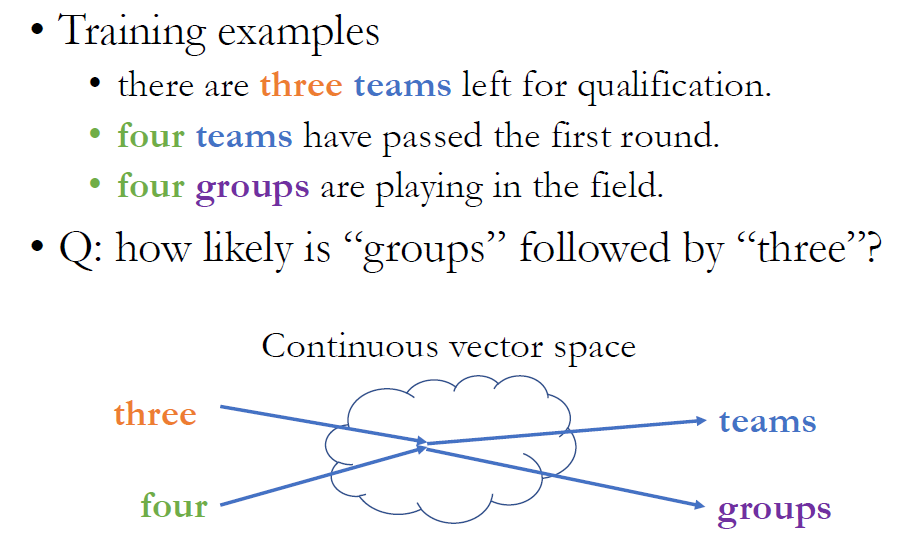
three teams, four teams, four groups는 있었지만 three groups는 나타나지 않았지만, three와 four가 비슷한 점으로 mapping이 되었기 때문에 추리할 수 있다.
- Three와 Four가 같은 곳에 매핑되지는 않지만 비슷한 곳에 매핑되게 된다.
- 이렇게 되면 test time에 input 에 three가 들어가면, three groups를 본 적이 없어도 team만이 아니라 group에도 높은 probability를 주게 된다.
실전에서 어떻게 Neural N-Gram Language Model을 어떻게 훈련시킬까?
데이터셋을 모은다. 데이터셋의 모든 n-gram을 추출한다.
Stochastic Gradient Descent를 할 때, 데이터 training example을 뽑을 때 최대한 uniform하게 뽑아야 하니까 shuffle을 한다.
뽑고싶은 만큼 100-1000개정도씩의 minibatch로 뽑고 이 network를 classifier training하듯이 하면 된다.
validation set을 이용해서 early-stopping을 해야 한다. Model의 architecture가 어떻게 될 지 정한다. architecture마다 hypothesis set이 하나가 생긴다.
골라진 hypothesis set 안에서 best model이 test set에 얼마나 잘 하는지 봐야 하는데 보통 language model의 척도로는 Perplexity라는 measure를 쓴다.
$$ppl = b^{\frac{1}{|D|}\sum_{(x_1,\cdots,x_N)\in D}log_b{p(x_N|x_1,\cdots,x_{N-1})}}$$
- test set의 모든 n- gram에 대해 log probability를 계산하고, average를 계산한 다음에 다시 exponentiation한다.
- Perplexity가 가지는 의미는 context를 봤을 때 그 다음 단어를 몇 개나 되는, 얼마나 작은 vocab subset안에서 고를 수 있는지를 알려준다.
- Perplexity가 1이라고 하면 testset의 모든 n-gram에 대해 input을 보면 다음 token이 뭐가 나올 지 완벽하게 볼 수 있는 것이고, perplexity가 10 이면 이 모델이 input을 봤을 때 그 다음 token이 뭐일지 10개 내외에서 맞출 수 있는 것이다.
- maximum perplexity는? vocab size와 같은 것.
- perplexity는 낮으면 낮을 수록 좋다. 낮을수록 scoring을 잘 하는 것이다.
- 그러나 실질적으로는 perplexity를 가지고 쓸 수 있는게 잘 없다.
Long Term Dependency
이전 단계의 토큰만 보기 때문에 long term dependency를 못 본다고 했었다. N이라는 숫자에 의해서. 그러면 이 문제는 어떻게 해결할 수 있을까?
- Context size를 막 늘린다. Count based인 N-gram문제에서는 그렇게 할 수 없었다(data sparsity)
- 하지만 continuous representation을 씀으로 그렇게 할 수 있다 (NN)
- 하지만 문제점 ?
- architecture size가 커지게 되고, 파라미터 개수도 많아지고, dataset도 커져야 한다.
- parameter들을 제대로 estimate하기 위해서.
Convolutional Language Model을 쓸 수 있다.
- convolutional layer하나마다 local하게 조금씩 보는건데, 위로 쌓으면서 더 넓은 영역을 볼 수 있다.
- Dilated Convolution을 그중에서 쓸 것이다.
- 더 빠르게 보는 size가 exponential하게 늘어날 수 있는가?
- 일반적인 convolution (아래 그림에서 색칠 없이 두줄만 본다)
- 쌓아봤자 2개, 5개 보게 되는것. N을 쭉 늘리기 위해 layer를 많이 쌓아야만 한다.
Dilated convolution
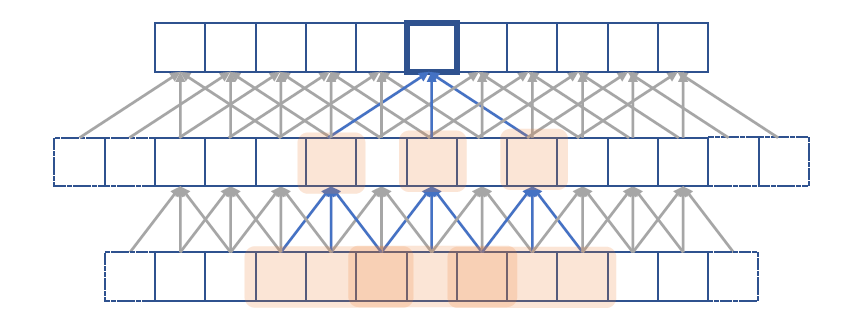
- layer를 쌓을 때 마다 중간중간에 구멍을 뚫어 놓는것.
- 똑같이 아래층의 3개를 보더라도 중간을 띄고 봄으로써 size를 늘리는 효과.
- 그냥 convolution을 생각없이 쓰다 보면, 다음 token을 맞추기 위해 미래 token도 사용해서 보게 되기 때문에 exact decomposition이 안 된다.
그래서 미래 token은 mask out하고 이전 단계의 token만 보도록 한다. automated하게 코드를 짤 수 있다.
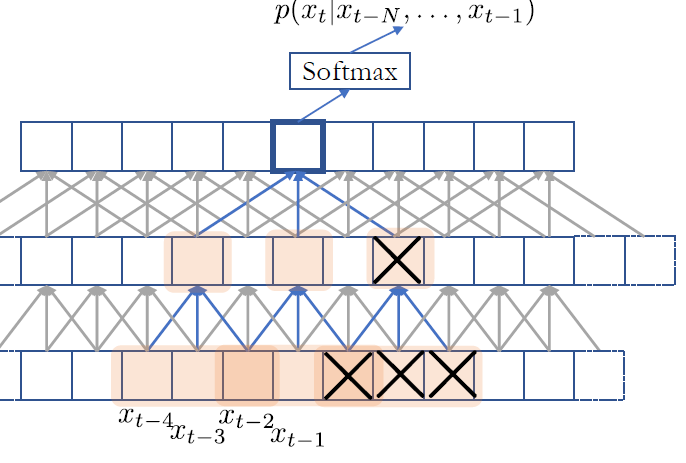
computation efficiency도 올라가고, number of parameter수도 너무 빠르게 올라가지 않게 되며 N을 크게 늘릴 수 있는 효과를 보게 된다!
- 이 아이디어가 기본이 되어 ByteNet이라는 것도 나왔고, Glove, Pixel CNN, WaveNet…
- 다양한 종류의 Language Model이 나오게 된다. 안드로이드 google voice assistant에 WaveNet이 이미 들어가있다.
- Facebook Research에서 나온것 : Gated Convolutional Language Model
- Causal structure를 capture하는 것이다. Generate할 때 causality modelling
Text Classification할 때는 과거 미래 등 상관 없이 문장 전체를 사용해서 찾아도 되는데, Language Modelling할 때는 generation하는 속도를 따라가야 하기 때문에 미래의 토큰을 사용해서 과거를 예측하면 안 된다.
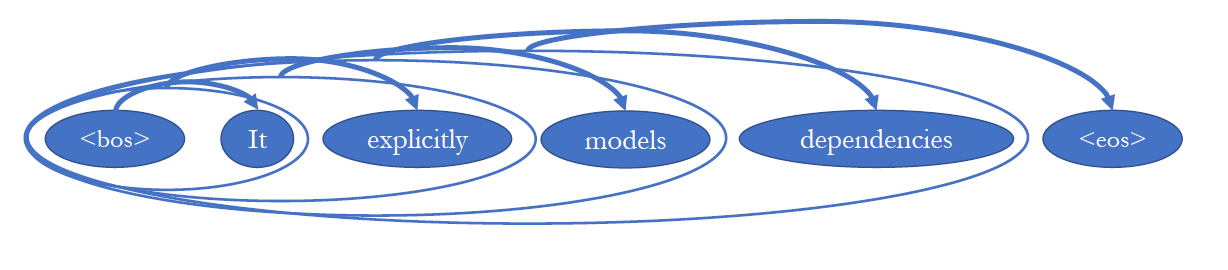
begin of sentence - Neural N-gram, convolutional 아니어도 지금까지 배운 어떤 sentence language model이면 이 causal structure만 따라가면 만들 수 있다. Context size자체를 infinite하게 늘릴 수 있다.
n이 infinite하게 갈 때 CBoW Language Model
- 매번 다음 토큰을 predict하기전에 average하는 token은 그전에 나온것만 사용하도록.
- CBoW가 classification에는 효과적이지만 Langauge Model에는 효과적이지 않다.
- 의미에 관련. Language Model에서는 구조 자체가 중요하기 때문에 순서를 무시하는 이런 sentence representation은 적합하지 않다.
- 그냥 어제 얘기한거라서 짚고 넘어감.
- CBoW를 사용한 LM이 잘하는 것은 Token representation을 잘 찾는다는점 때문에 Word2Vec 임베딩 찾는데 많이 쓰고, sentence scoring에 이걸 쓸 이유는 없다.
Recurrent Neural Network
- LM에 실제로 많이 쓰이는 모델
- Context를 infinite하게 늘리기 위해 online으로 여태 까지의 모든 token을 하나의 vector representation으로 표현하기 위해 사용
- 다만 한쪽 방향으로만 가야한다! (Bidirectional안됨)
- LM에 사용하기 위해서 미래 모델을 사용하지 못하니까, 과거 token들에 적용해서 summarization하고 softmax fn에 입력해서 distribution에서 score를 자동으로 계산.
- 실전에서 가장 많이 사용 speech recognition, 스마트폰 키보드 autocomplete할 때 , search engine에서 일부 사용
- search engine에서는 속도문제때문에 NN 제한적으로 사용
- Sentence Generation다른 문제들에서 중간중간에 scoring을 주니까 candidate들을 prune out할 때 많이 사용한다.
Self Attention
- RNN잘 쓰이지만 한 가지 문제점은 문장이 길어질 수록 prefix summary를 잘 못하게 된다.
- sequence가 주어졌을 때 vector 하나로 만드는데, 문장이 길어질 수록 기억하고 있어야 하는 내용들이 많아져서 RNN이 커져야하고, parameter 수가 많아지고, dataset이 커져야하는 악순환에 빠지게 된다.
- Attention은 매 step마다 그 전에 있던 모든 token에 대해 따로 계산을 해주기 때문에 하나의 vector로 사용할 필요가 없다.
- 그래서 RNN과 self attention을 같이 사용하게 된다.
- Recurrent memory network
- RNN을 돌려서 summarize된 하나의 벡터만을 사용하는 것이 아니라, 그 벡터를 기준으로 그전의 모든 벡터들과 pairwise comparison을 한다. (weighting function과 relational Network function을 사용)
- weighting function이 기존에 있던 token들중 뭐가 중요한지 보고 고른다.
- 그 전 다섯개 토큰 중 무엇이 가장 중요했는지 골라서 다음번 token을 예측할 때 사용하게 된다.
- 지금까지 본 모든 token을 압축해서 하나에 넣을 필요가 없어진다.
- 이 논문 소개에서는문장 중간중간 빈 공간을 채우는 문제에서 Recurrent NN이 잘 작동했다.
- Recurrent Memory Network이 이전에 있던 것들보다 잘 된다.
- DAG안에 들어만 가면 어떻게든 원하는대로 붙일 수 있기 때문에 섞어서 쓰는 것이 가능하고, 문제에 따라 잘 섞어서 쓰면 성능과 효율성이 올라간다.
- Google Translation team : RNMT 에 rnn + self attention모델 사용함.
Summary
- Language Model
- Sentence의 score, probability가 뭐냐.
- Autoregressive Language Model
- 왼쪽에서 오른쪽으로 넘어가면서 probability를 계산.
- 장점 : language model이라는것 자체는 unsupervised인데 ARLM 은 supervised문제 (text classification)으로 바꾸었다.
- Count based N-gram Language Model의 문제점
- Data Sparsity
- Long-term Dependency
- NN을 사용함으로써 어떻게 해결이 되었는지
- 다섯가지 sentence representation방법 (section C) 로 text classification, language modelling, machine translation, question answering등 다양하게 사용할 수 있다.
Q & A
- 업데이트예정
잘 이해했는지 확인할 수 있는 질문 (생각해보세요)
- Language Model이란 무엇인가?
- Autoregressive Model은 무엇인가? 장점은 무엇인가?
- Count based N-gram Language Model의 문제점 두 가지는 무엇인가?
- 각각의 문제를 해결하기 위해 제시된 방법들은 무엇인가?
- NN을 사용하면 어떤 문제가, 왜 해결될 수 있는가?
